
HyperFinity 如何利用 Snowflake 的 Snowpark for Python 簡化其無伺服器架構
HyperFinity 是一個決策科學 SaaS 平臺。透過機器學習和人工智慧、嵌入式分析和資料視覺化,HyperFinity 使非技術使用者能夠做出資料驅動的決策,並建立簡單的輸出以支援下游系統,例如 CRM、ERP 或內容管理系統。這使得組織能夠快速地在多個領域做出由機器學習驅動的決策,從更智慧的供應鏈到最佳化的定價。
Snowflake 是 HyperFinity 資料密集型平臺的核心。除了廣泛的資料型別支援(例如半結構化資料的變體資料型別)之外,Snowflake REST API 和零拷貝克隆等其他功能在平臺的無伺服器架構中也發揮著寶貴的作用。Snowflake 的安全資料共享還簡化了 ELT 流程,並簡化了 HyperFinity 平臺及其輸出與已經使用 Snowflake 的客戶的整合。
挑戰:不同程式語言採用不同的基礎設施
雖然 HyperFinity 的平臺是為非技術使用者設計的,只需點選一下即可輕鬆應用機器學習和人工智慧,但所有所需的資料處理功能都是由專注於資料科學的團隊開發的,他們的主要編碼語言是 SQL 和 Python。Snowflake 處理了我們所有的 SQL 開發和處理,但為了為我們的 Python 程式碼構建一個無伺服器計算引擎,我們的團隊必須在 AWS 上建立一套新的雲基礎設施,這需要將多個計算服務(如 Amazon EC2 和 AWS Lambda)連線起來。這有幾個缺點,例如不得不將資料移出 Snowflake 的治理邊界進行處理,維護額外的基礎設施,以及編寫額外的程式碼來處理服務之間資料結構的變化。
當我們看到Snowpark 對 Python 的支援釋出時,我們對它可能帶來的可能性感到非常興奮,我們也非常幸運地參與了私人預覽。
使用 Snowpark for Python 簡化我們的架構
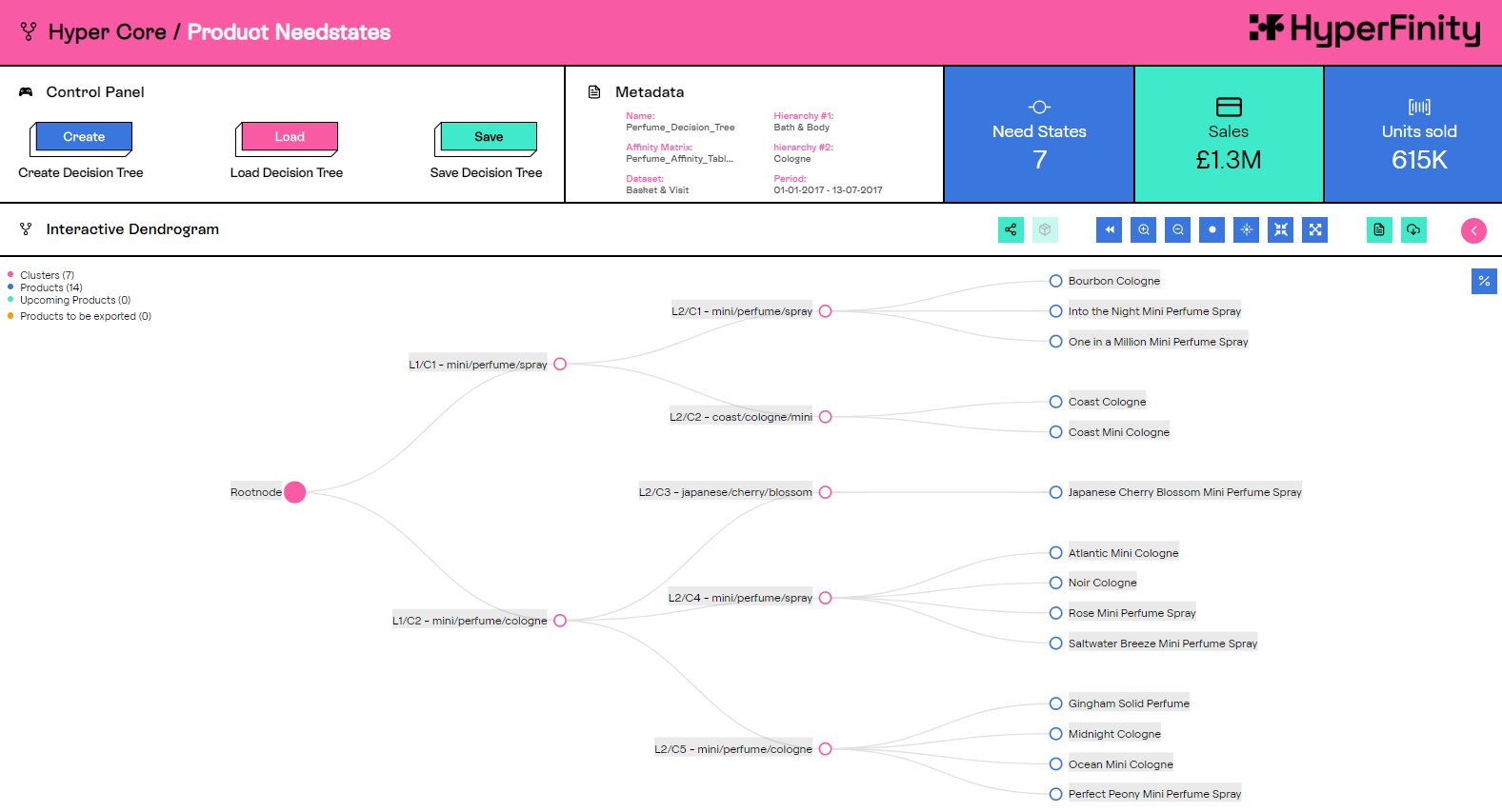
Python 的優勢之一是其豐富的開源包和庫生態系統,我們廣泛使用了這些包和庫。例如,平臺的核心部分是為產品組建立“客戶需求狀態”。這使用了一種稱為層次聚類的技術來建立客戶決策樹,它表示個人為購買產品而做出的選擇。計算這些需求狀態需要矩陣和陣列乘法,我們的團隊在 Snowpark 中使用 Python 庫 numpy 和 scipy 利用了這一點。透過使用 Snowpark,這種型別的計算在 Snowflake 中開發和實現要簡單得多。
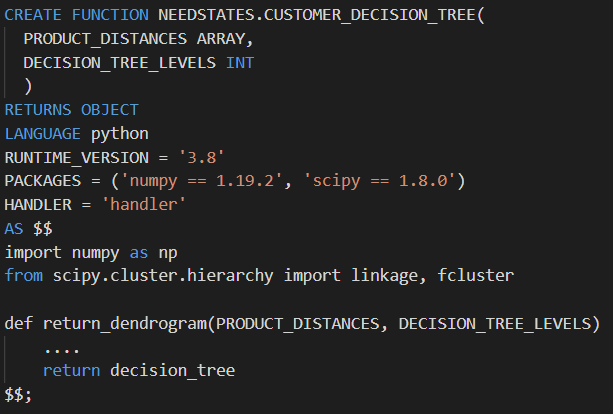
以前用於 Python 處理的雲基礎設施被簡單的 Snowpark 程式碼取代
由於 Snowpark for Python 環境透過 Snowflake 與 Anaconda 的合作預裝了 1,000 多個庫,我們可以輕鬆地遷移現有功能,只需極少的精力。擁有最流行的庫可以消除開發過程中的另一層管理,並且透過整合的 conda 包管理器,無需擔心依賴管理。如果我們需要自定義庫,Snowflake 支援上傳和匯入自定義 Python 程式碼的能力。
我們還能夠以一種以前需要資料在多個工具之間來回傳輸的方式將 SQL 和 Python 邏輯融合在一起,我們的團隊還透過並行處理獲得了更高的效能。透過 SQL 和 Python 的這種融合,我們可以在多個 SQL 行上同時執行用 Python 編寫的邏輯,將以前的迴圈操作變成並行處理。例如,以五種不同深度執行我們的聚類解決方案所需的時間與以一種深度執行所需的時間相同。
“Snowpark 使我們能夠加速開發,同時降低與資料移動以及為 SQL 和 Python 執行獨立環境相關的成本。”
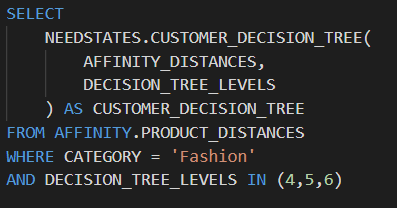
在 Snowflake 中將 Python 函式作為 SQL 語句的一部分執行,包括並行處理
將我們的 Python 程序遷移到 Snowpark 消除了我們架構中不必要的複雜性,並透過刪除處理服務之間資料結構變化的所有額外程式碼來簡化了我們的開發。現在,我們的團隊可以在資料儲存的相同環境中開發、測試和部署他們的 Python 程式碼,利用 Snowflake 平臺的力量,並使用他們首選的開發語言。
HyperFinity 是一款旨在簡化決策的軟體,它利用強大的資料科學和高階分析技術。Snowflake,以及現在的 Snowpark,是 HyperFinity 架構的重要組成部分,我們對 Snowflake 為軟體帶來的效能和穩定性以及 Snowflake 釋出的新功能,使其工作起來更加強大,感到非常滿意。
作為一家初創公司,在 Snowflake 的基礎上構建我們的應用程式簡化了我們的基礎設施和開發過程,並加速了軟體的上市程序。